Discovering equations from data using SINDy
Created:
Topic: Scientific ML techniques
Introduction
Suppose you’ve collected data from a physical system, and you need to make predictions based on that data. You could try training a neural network on your data, then use the neural network to make predictions — this might work for dynamics similar to the observed ones. However, it won’t help you understand the underlying physics of the system, and it won’t enable you to generalize to other systems governed by the same physical principles but with different characteristics. For example, a neural network trained on data from a swinging pendulum might always predict that a pendulum swings back and forth. However, if we learned the underlying physical equation, we could predict that when the angular velocity is large enough, it will transition to a motion where it rotates continuously in one direction. This ability to extrapolate has the potential to advance the physical sciences through new discoveries.
In this blog post, I’ll discuss one popular method for discovering governing equations for nonlinear dynamical systems: SINDy (Sparse Identification of Nonlinear Dynamics). The code and text in this post are based on the 2016 paper “Discovering governing equations from data by sparse identification of nonlinear dynamical systems” by Brunton, Proctor, and Kutz, and its accompanying Matlab code.
This is a useful technique if you’ve gathered data that evolves over time, and want to find a system of ordinary differential equations (ODEs) that describes and predicts this evolution. Scenarios that fall in this category are common in the physical sciences, such as biology, climate science, and neuroscience. In this post, we’ll use the nonlinear three-dimensional Lorenz system of equations as a basis for our experiments. But the main ideas you’ll learn here can be applied to any observed data that you suspect can be represented as a system of ODEs.
My Python code can be found on github. I encourage you to follow along on github as you read this article — the files I will mention are all under the sindy/lorenz-custom and sindy/lorenz-pysindy directories.
The main idea of the paper
SINDy aims to learn nonlinear dynamical systems from data. Assume we observe a sequence of
We suppose that
Note that the original SINDy paper and this post focus on systems of ordinary differential equations (meaning that
I’ll start by reminding you of the basics of linear regression. This is a foundational concept, and you can skip the next section if you already understand it well.
Linear regression
We’ll take a brief look at linear regression in this section.
The goal of linear regression is to model the relationship between two variables, an
Let’s look at the equation that describes the linear relationship that we would like to establish between these two variables:
We’ll assume that we have
Visually, if our data points have just one feature (so
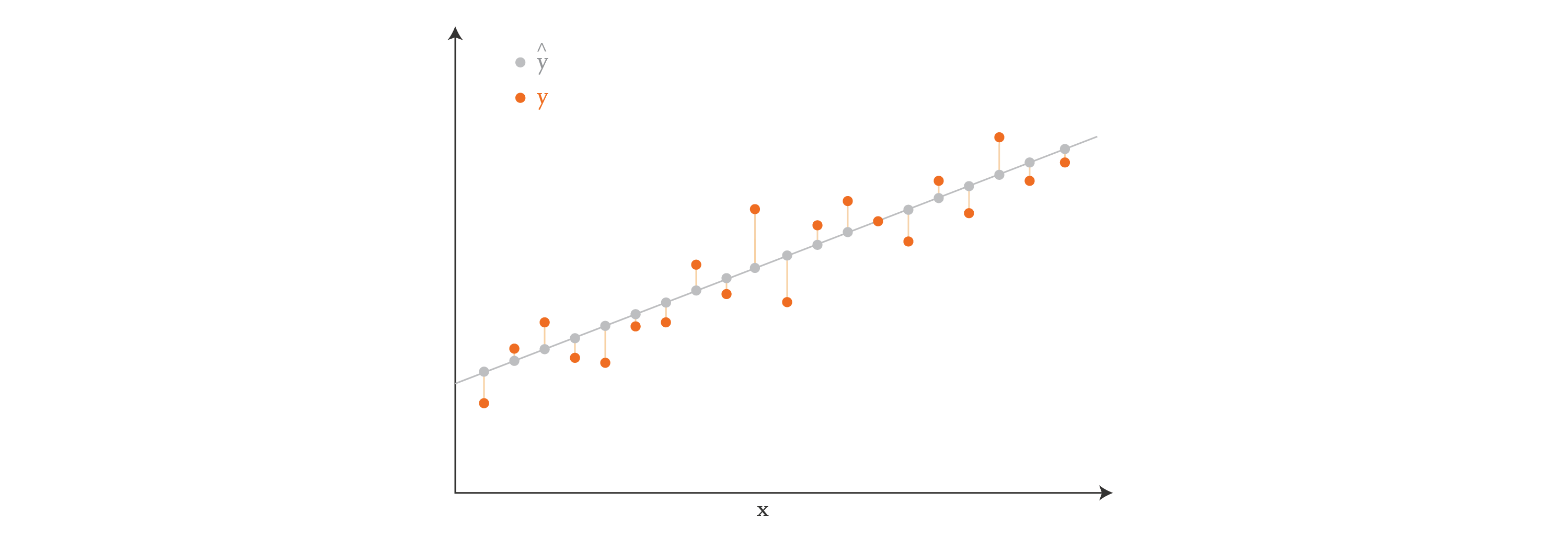
If our data points were two-dimensional, then we would be finding a plane instead of a line. And if they were
In the context of machine learning, it’s common to write the relationship between
In this equation,
In the equation above, the target values
Often our goal is not just to get the best
Back to main idea of the paper
So, how do linear regression and sparsity relate to the SINDy paper? Remember the ordinary differential equation that we’re trying to find:
We have samples of
For example, if someone else gives us data that was generated by the Lorenz system without telling us how it was generated, we would be successful in discovering the equations as long as we include low-degree polynomials in our set of candidate functions. That’s because the Lorenz system looks like this:
So, in this case, as long as we include
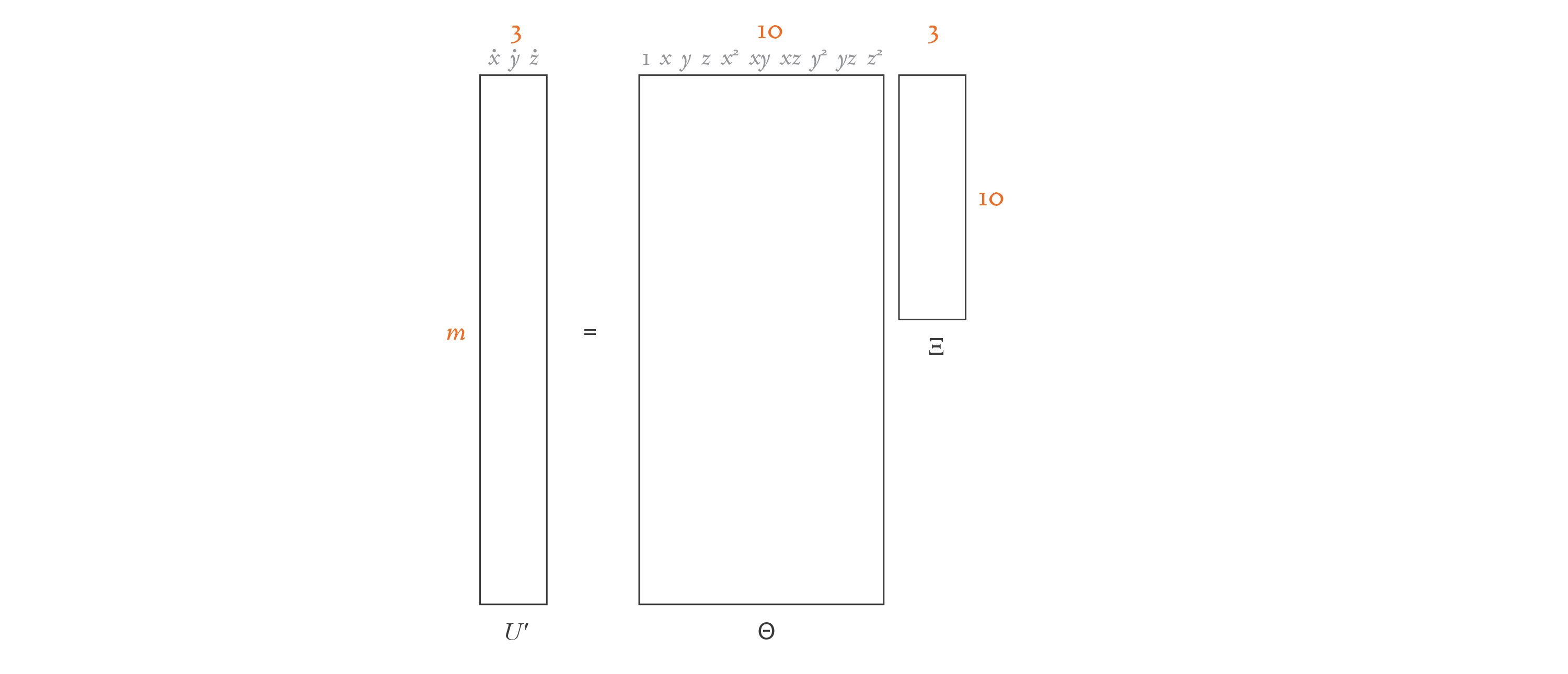
In the general scenario, we can express the derivatives as a linear combination of candidate functions, as follows:
In the equation above,
The matrix
The matrix
Here’s a diagram that demonstrates the structure of our equation for this simple example:
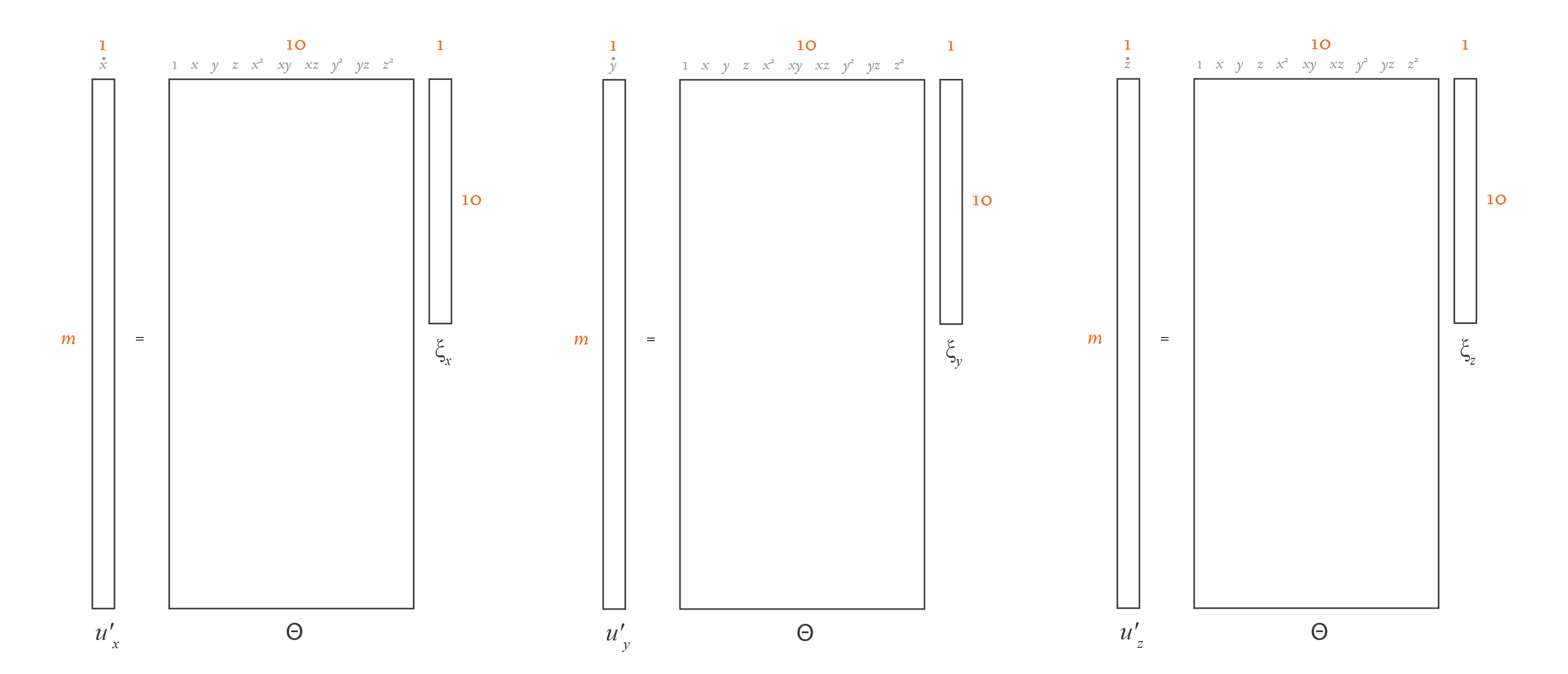
If you compare this equation with the linear regression one in the previous section, you’ll see that the overall structure is the same. The only difference is that
As I mentioned earlier, LASSO is a popular method for solving linear regression problems while optimizing for a sparse solution. However, the authors of the paper found LASSO to be algorithmically unstable and computationally expensive for very large data sets, so they designed an alternative: the “Sequential Thresholded Least-Squares” algorithm.
Fitting using Sequential Thresholded Least-Squares
In the next three sections, I will explain each of the three main Python files in the accompanying project:
sindy/lorenz-custom/src/1_generate_data.py— Generates sample dataand calculates its derivatives . sindy/lorenz-custom/src/2_fit.py— Discovers a sparse equation that represents our data well, using the Sequential Thresholded Least-Squares algorithm.sindy/lorenz-custom/src/3_predict.py— Uses the discovered equation to predict a trajectory, given an initial condition.
I’ll begin with the second file, since that’s where the SINDy paper brings the most innovation. Here’s my Python implementation of the Sequential Thresholded Least-Squares algorithm:
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-custom/src/2_fit.py
import numpy as np
def calculate_regression(theta: np.ndarray, uprime: np.ndarray,
threshold: float, max_iterations: int) -> np.ndarray:
"""Finds a xi matrix that fits theta * xi = uprime, using the sequential
thresholded least-squares algorithm, which is a regression algorithm that
promotes sparsity.
The authors of the SINDy paper designed this algorithm as an alternative
to LASSO, because they found LASSO to be algorithmically unstable, and
computationally expensive for very large data sets.
"""
# Solve theta * xi = uprime in the least-squares sense.
xi = np.linalg.lstsq(theta, uprime, rcond=None)[0]
n = xi.shape[1]
# Add sparsity.
for _ in range(max_iterations):
small_indices = np.abs(xi) < threshold
xi[small_indices] = 0
for j in range(n):
big_indices = np.logical_not(small_indices[:, j])
xi[big_indices, j] = np.linalg.lstsq(theta[:, big_indices],
uprime[:, j],
rcond=None)[0]
return xi
In the code above, the theta input parameter contains the uprime input parameter contains the threshold and max_iterations input parameters help us fine-tune the Sequential Threasholded Least-Squares algorithm, as we’ll see soon.
The first operation in this algorithm is to calculate a least-squares solution to the equation using a direct method, which is a great starting point:
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-custom/src/2_fit.py
xi = np.linalg.lstsq(theta, uprime, rcond=None)[0]
Below is one potential result for this operation. Remember that the
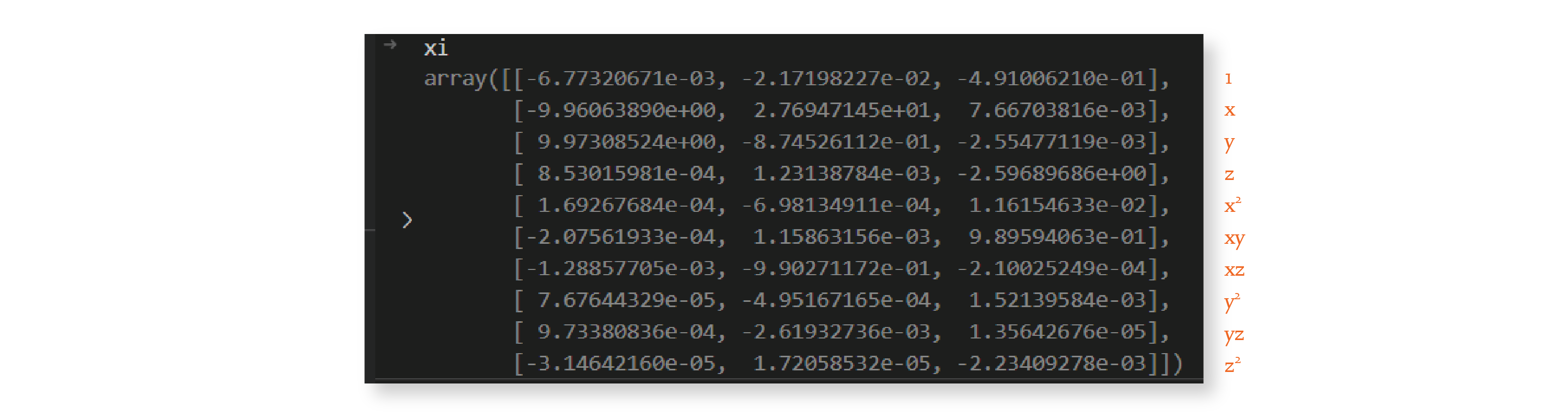
This matrix solves the equation, but as you can see, it’s not sparse. The role of the for loop that follows is to introduce sparsity to the matrix, while compromising as little as possible on the accuracy of the solution. The code first identifies all the matrix locations with coefficients smaller than the threshold passed as a parameter, and sets those coefficients to zero:
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-custom/src/2_fit.py
for _ in range(max_iterations):
small_indices = np.abs(xi) < threshold
xi[small_indices] = 0
for j in range(n):
big_indices = np.logical_not(small_indices[:, j])
xi[big_indices, j] = np.linalg.lstsq(theta[:, big_indices],
uprime[:, j],
rcond=None)[0]
Then, it solves the least-squares problem considering only the remaining non-zero coefficients. However, because we may have a different number of non-zero coefficients in each column of
Let’s look at what the threshold value 0.025:
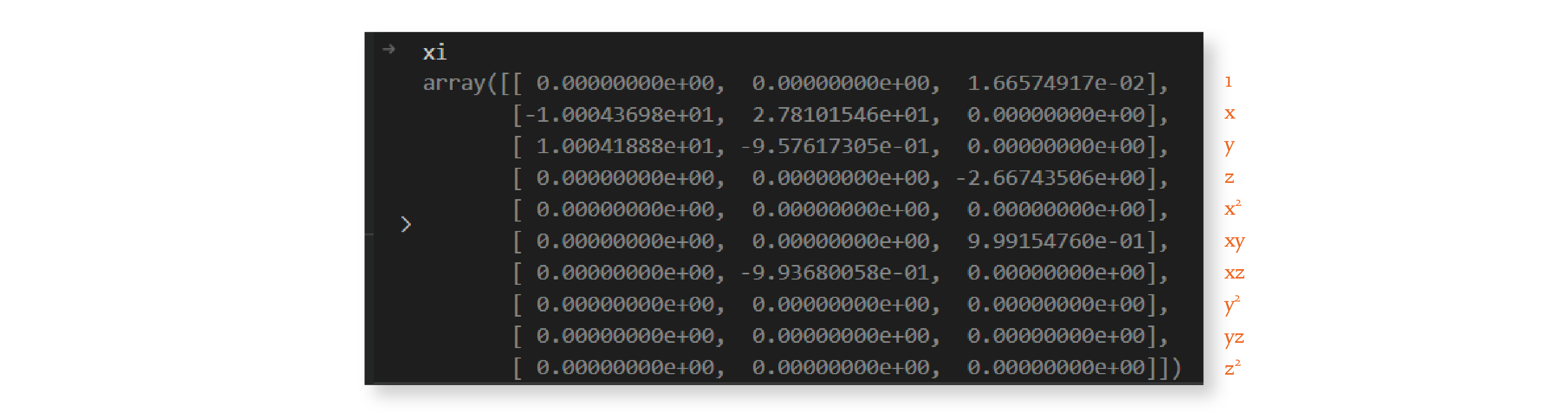
The matrix is much sparser now. We repeat this procedure 9 more times because we set max_iterations to 10, and by the end, we have the following matrix:
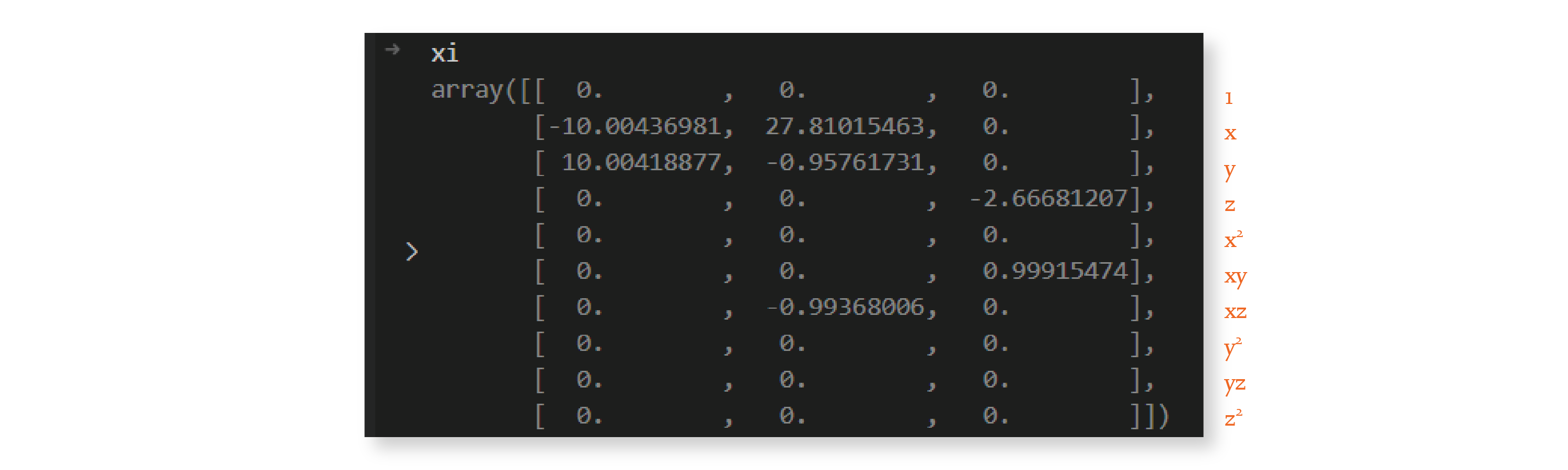
And we’re done — we discovered a sparse
As you can see, the system discovered by this algorithm is very similar to the Lorenz system with parameters
The small differences between the predicted and actual coefficients are due to noise in the calculation of the derivatives. We’ll also come back to this in the next section.
Let’s now take a look at the main function in this file. As you can see, it has two steps: it creates the
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-custom/src/2_fit.py
from common import POLYNOMIAL_ORDER, USE_TRIG, THRESHOLD, MAX_ITERATIONS, create_library
def main() -> None:
...
theta = create_library(u, POLYNOMIAL_ORDER, USE_TRIG)
xi = calculate_regression(theta, uprime, THRESHOLD, MAX_ITERATIONS)
...
Let’s now look at the code that generates the
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-custom/src/common.py
import numpy as np
def create_library(u: np.ndarray, polynomial_order: int,
use_trig: bool) -> np.ndarray:
"""Creates a matrix containing a library of candidate functions.
For example, if our u depends on x, y, and z, and we specify
polynomial_order=2 and use_trig=false, our terms would be:
1, x, y, z, x^2, xy, xz, y^2, yz, z^2.
"""
(m, n) = u.shape
theta = np.ones((m, 1))
# Polynomials of order 1.
theta = np.hstack((theta, u))
# Polynomials of order 2.
if polynomial_order >= 2:
for i in range(n):
for j in range(i, n):
theta = np.hstack((theta, u[:, i:i + 1] * u[:, j:j + 1]))
# Polynomials of order 3.
if polynomial_order >= 3:
for i in range(n):
for j in range(i, n):
for k in range(j, n):
theta = np.hstack(
(theta, u[:, i:i + 1] * u[:, j:j + 1] * u[:, k:k + 1]))
# Polynomials of order 4.
if polynomial_order >= 4:
for i in range(n):
for j in range(i, n):
for k in range(j, n):
for l in range(k, n):
theta = np.hstack(
(theta, u[:, i:i + 1] * u[:, j:j + 1] *
u[:, k:k + 1] * u[:, l:l + 1]))
# Polynomials of order 5.
if polynomial_order >= 5:
for i in range(n):
for j in range(i, n):
for k in range(j, n):
for l in range(k, n):
for m in range(l, n):
theta = np.hstack(
(theta, u[:, i:i + 1] * u[:, j:j + 1] *
u[:, k:k + 1] * u[:, l:l + 1] * u[:, m:m + 1]))
if use_trig:
for i in range(1, 11):
theta = np.hstack((theta, np.sin(i * u), np.cos(i * u)))
return theta
This function takes the data polynomial_order parameter is set to 2. And we don’t want to consider trigonometric candidate functions, so the use_trig parameter is set to False.
Let’s now look at how we generate the data
Generation of data and derivatives
In a real-world project, you would set up an experiment, and you would measure your data
Let’s see the code that generates
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-custom/src/1_generate_data.py
import numpy as np
from scipy.integrate import solve_ivp
from common import BETA, RHO, SIGMA
def lorenz(_: float, u: np.ndarray, sigma: float, rho: float,
beta: float) -> np.ndarray:
"""Returns a list containing values of the three functions of the Lorenz system.
The Lorenz equations have constant coefficients (that don't depend on t),
but we still receive t as the first parameter because that's how the
integrator works.
"""
x = u[0]
y = u[1]
z = u[2]
dx_dt = sigma * (y - x)
dy_dt = x * (rho - z) - y
dz_dt = x * y - beta * z
return np.hstack((dx_dt, dy_dt, dz_dt))
def generate_u(t: np.ndarray) -> np.ndarray:
"""Simulates observed data u with the help of an integrator for the Lorenz
equations.
"""
u0 = np.array([-8, 8, 27])
result = solve_ivp(fun=lorenz,
t_span=(t[0], t[-1]),
y0=u0,
t_eval=t,
args=(SIGMA, RHO, BETA))
u = result.y.T
return u
Here, we use SciPy’s solve_ivp function to get the Lorenz solution with initial value u0. If you’ve used Matlab before to work with differential equations, you likely used the ode45 function to solve them — solve_ivp is one way to do the same in Python. We need to tell the solve_ivp function the timesteps of our trajectory, which we store in variable t. In this case, the length of t determines the length of the trajectory returned by solve_ivp. We also need to specify the parameters of the Lorenz system, which we define elsewhere to be
We now have an array of three-dimensional values that represent a portion of a trajectory in the Lorenz system. But remember that we don’t need the actual data samples
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-custom/src/1_generate_data.py
from derivative import dxdt
def calculate_finite_difference_derivatives(u: np.ndarray,
t: np.ndarray) -> np.ndarray:
"""Calculates the derivatives of u using finite differences.
Finite difference derivatives are quick and simple to calculate. They
may not do as well as total variation derivatives at denoising
derivatives in general, but in our simple non-noisy scenario, they
do just as well.
"""
logging.info("Using finite difference derivatives.")
uprime = dxdt(u.T, t, kind="finite_difference", k=1).T
return uprime
I’m using the derivative Python package here, so I don’t need to provide my own implementation of the algorithm. You can use the same package to calculate total variation derivatives with regularization (which I show in the code for this project), among many other methods.
Using a numerical method to calculate derivatives will always introduce a bit of noise, which is why the equations we discovered aren’t exactly like the original ones, as you saw in the previous section. In this scenario, because we know the equations used to generate the data, we can generate exact derivatives by simply plugging our data
Let’s now look at the function that calls the code that generates
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-custom/src/1_generate_data.py
def generate_data() -> Tuple[np.ndarray, np.ndarray]:
""" Generates data u, and calculates its derivatives uprime.
"""
t0 = 0.001
dt = 0.001
tmax = 100
n = int(tmax / dt)
t = np.linspace(start=t0, stop=tmax, num=n)
# Step 1: Generate data u.
u = generate_u(t)
# Step 2: Calculate u' from u.
uprime = calculate_finite_difference_derivatives(u, t)
return (u, uprime)
As you can see, we create a list of timestamps t, which we then use in the two main steps of this file: the generation of the data
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-custom/src/1_generate_data.py
def main() -> None:
...
(u, uprime) = generate_data()
...
Making a prediction
In the last two sections, we explored the code in the following Python files:
sindy/lorenz-custom/src/1_generate_data.py— Generates our datafrom the Lorenz system, and calculates derivatives using the finite differences numerical method. sindy/lorenz-custom/src/2_fit.py— Generates amatrix containing candidate functions for the equation we want to discover, and uses the Sequential Thresholded Least-Squares algorithm to discover that equation.
In this section, we’ll explore the code in the third and final file, sindy/lorenz-custom/src/3_predict.py, where we’ll make a prediction.
Let’s think about what it means to make a prediction in this scenario. In our “fit” code we discovered a system of ordinary differential equations based on our data. Therefore, if we’re given an initial condition, we should be able to integrate the differential equation we discovered and get a trajectory that predicts future values. We’ve already seen how to integrate an ordinal differential equation using the solve_ivp function, when we generated our data
We generated
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-custom/src/3_predict.py
import numpy as np
from scipy.integrate import solve_ivp
from common import POLYNOMIAL_ORDER, USE_TRIG, create_library
def lorenz_approximation(_: float, u: np.ndarray, xi: np.ndarray,
polynomial_order: int, use_trig: bool) -> np.ndarray:
"""For a given 1 x 3 u vector, this function calculates the corresponding
1 x n row of the theta matrix, and multiples that theta row by the n x 3 xi.
The result is the corresponding 1 x 3 du/dt vector.
"""
theta = create_library(u.reshape((1, 3)), polynomial_order, use_trig)
return theta @ xi
def compute_trajectory(u0: np.ndarray, xi: np.ndarray, polynomial_order: int,
use_trig: bool) -> np.ndarray:
"""Calculates the trajectory of the model discovered by SINDy.
Given an initial value for u, we call the lorenz_approximation function
to calculate the corresponding du/dt. Then, using a numerical method,
solve_ivp uses that derivative to calculate the next value of u, using the
xi matrix discovered by SINDy. This process repeats, until we have all
values of the u trajectory.
"""
t0 = 0.001
dt = 0.001
tmax = 100
n = int(tmax / dt + 1)
t = np.linspace(start=t0, stop=tmax, num=n)
result = solve_ivp(fun=lorenz_approximation,
t_span=(t0, tmax),
y0=u0,
t_eval=t,
args=(xi, polynomial_order, use_trig))
u = result.y.T
return u
def main() -> None:
...
u0 = np.array([-8, 8, 27])
u_approximation = compute_trajectory(u0, xi, POLYNOMIAL_ORDER, USE_TRIG)
...
The compute_trajectory function should be familiar to you by now — it calculates a trajectory for the lorenz_approximation function, given an initial value and list of timestamps t. The lorenz_approximation function implements the equation we discovered. The result, u_approximation, is our prediction for the trajectory that starts at u0.
Let’s take a look at the original Lorenz trajectory, and the trajectory predicted by SINDy, side-by-side.
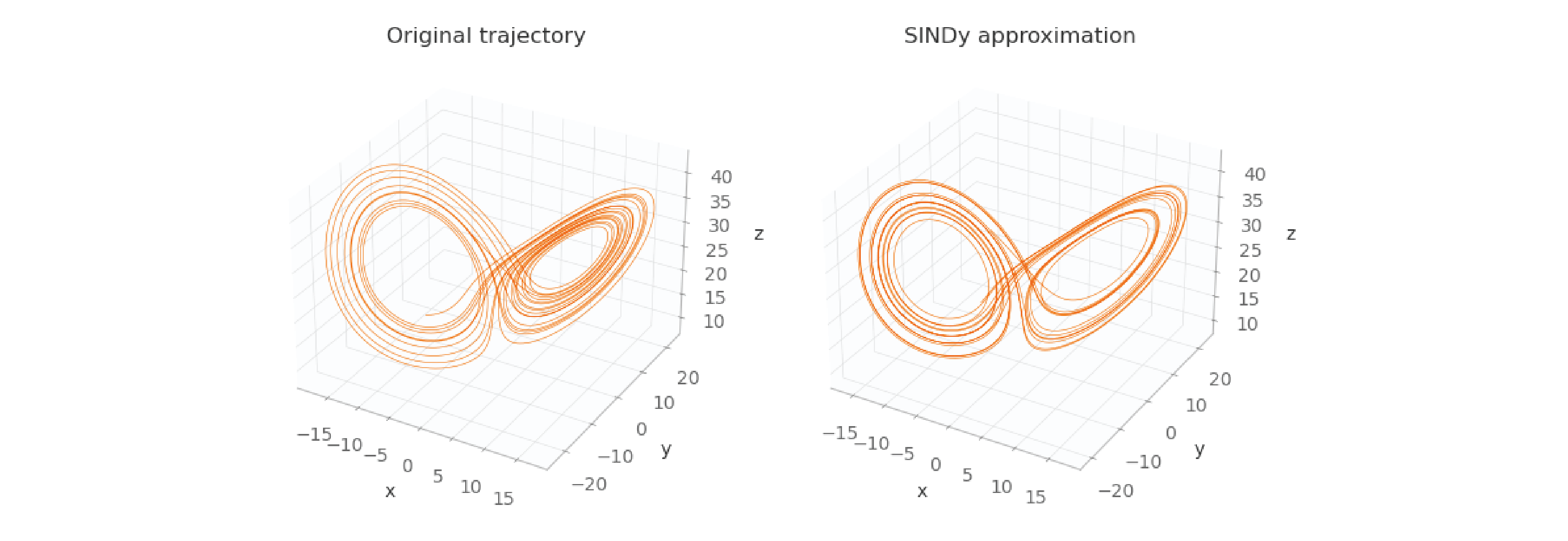
As you can see, the images aren’t exactly the same (because the equations discovered by SINDy aren’t exactly the same as the originals), but they’re very close. In the derivative calculation step, if instead of finite differences we had used exact derivatives, these two images would be exactly the same.
PySindy
Up until now, we explored the implementation of the basic ideas of SINDy, to help you understand its nuts and bolts. However, now that the PySINDy package is available, it’s much easier to just use that instead.
Let’s take a look at how the “fit” file changes if we use PySINDy. This code can be found on github under the sindy/lorenz-pysindy directory.
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-pysindy/src/2_fit.py
import numpy as np
import pysindy as ps
from pysindy.differentiation import FiniteDifference
from pysindy.optimizers import STLSQ
from common import MAX_ITERATIONS, THRESHOLD
def fit(u: np.ndarray, t: np.ndarray) -> ps.SINDy:
"""Uses PySINDy to find the equation that best fits the data u.
"""
optimizer = STLSQ(threshold=THRESHOLD, max_iter=MAX_ITERATIONS)
differentiation_method = FiniteDifference()
model = ps.SINDy(optimizer=optimizer,
differentiation_method=differentiation_method,
feature_names=["x", "y", "z"],
discrete_time=False)
model.fit(u, t=t)
model.print()
logging.info("xi: %s", model.coefficients().T)
return model
def main() -> None:
...
model = fit(u, t)
...
This is much simpler than the previous project. Instead of implementing the Sequential Thresholded Least-Squares algorithm from scratch, we can simply call pysindy.optimizers.STLSQ(...). Also, we no longer need to create our own fit to train it. In this scenario, training means discovering the unknown coefficients for
Then in the 3_predict.py file, instead of using the lower-level solve_ivp(...) method, we can now simply call model.simulate(...) to get our predicted trajectory.
https://github.com/bstollnitz/sindy/tree/main/sindy/lorenz-pysindy/src/3_predict.py
def compute_trajectory(u0: np.ndarray, model: ps.SINDy) -> np.ndarray:
"""Calculates the trajectory using the model discovered by SINDy.
"""
t0 = 0.001
dt = 0.001
tmax = 100
n = int(tmax / dt + 1)
t_eval = np.linspace(start=t0, stop=tmax, num=n)
u_approximation = model.simulate(u0, t_eval)
return u_approximation
def main() -> None:
...
u0 = np.array([-8, 8, 27])
u_approximation = compute_trajectory(u0, model)
...
This code is also much simpler. Let’s now look at a visual representation of the original trajectory and the prediction made by PySINDy:
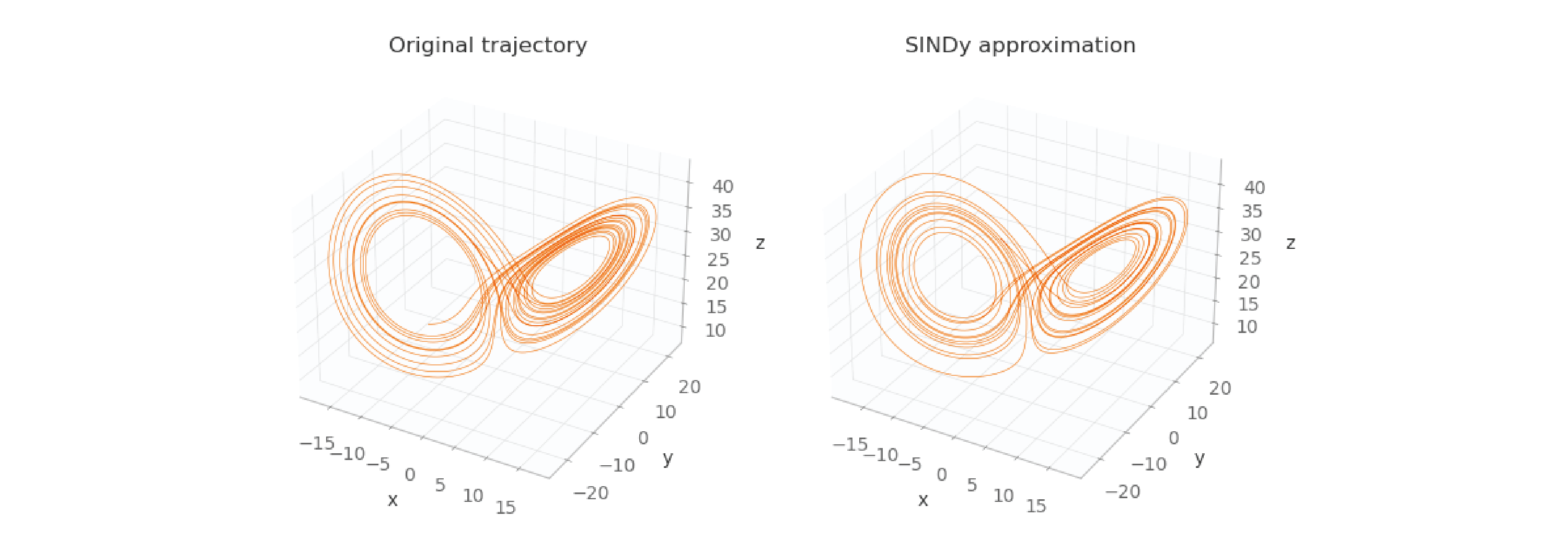
The two trajectories are really close, maybe closer than the trajectory created using custom code. That’s likely because PySINDy implements not only the ideas of the original paper, but also improvements to those ideas made by many subsequent papers.
Conclusion
In this blog post, you learned about discovering non-linear systems of ordinary differential equations from data, using the ideas in the original SINDy paper. I first showed you how to implement the algorithms in the paper from scratch, and then I showed how to use the PySINDy API to accomplish the same task.
The Python code for this project can be found on github.
I hope that you learned something new, and that you’re inspired to use this technique with your own data. Thank you for reading!