How GPT models work: accessible to everyone
Created:
Updated:
Topic: Large Language Models
How generative language models work
GPT models have been making the news, and many people are wondering how they’re implemented. While the details of their inner workings are proprietary and complex, their basic ideas are public and simple enough for everyone to understand. My goal for this post is to explain the basics of generative models in general and GPT models in particular, in a way that’s accessible to a general audience. If you’re an AI expert, check out my equivalent post for an AI audience.
Let’s start by exploring how generative language models work. The very basic idea is the following: they take
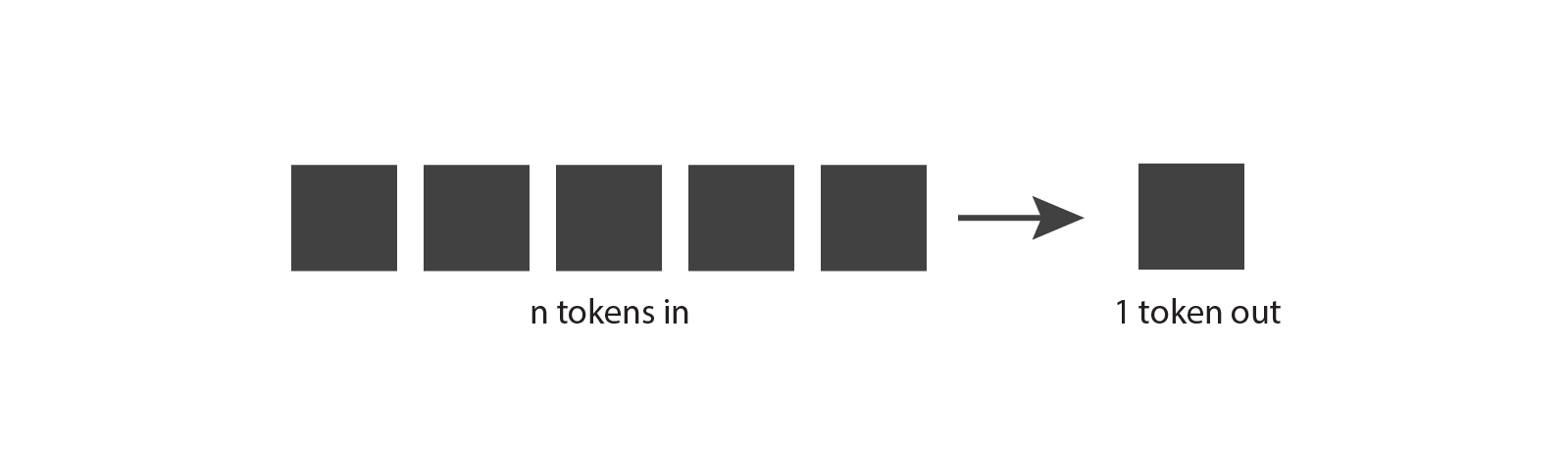
This seems like a fairly straightforward concept, but in order to really understand it, we need to know what a token is.
A token is a chunk of text. In the context of OpenAI GPT models, common and short words typically correspond to a single token, such as the word “We” in the image below. Long and less commonly used words are generally broken up into several tokens. For example the word “anthropomorphizing” in the image below is broken up into three tokens. Abbreviations like “ChatGPT” may be represented with a single token or broken up into multiple, depending on how common it is for the letters to appear together. You can go to OpenAI’s Tokenizer page, enter your text, and see how it gets split up into tokens. Or you can use their open-source tiktoken library to tokenize using Python code.

This gives you a good intuition for how OpenAI’s tokenizer works, but you may be wondering why they chose those token lengths. Let’s consider some other options for tokenization. Suppose we try the simplest possible implementation, where each letter is a token. That makes it easy to break up the text into tokens, and keeps the total number of different tokens small. However, we can’t encode nearly as much information as in OpenAI’s approach. If we used letter-based tokens in the example above, 11 tokens could only encode “We need to”, while 11 of OpenAI’s tokens can encode the entire sentence. It turns out that the current language models have a limit on the maximum number of tokens that they can receive. Therefore, we want to pack as much information as possible in each token.
Now let’s consider the scenario where each word is a token. Compared to OpenAI’s approach, we would only need seven tokens to represent the same sentence, which seems more efficient. And splitting by word is also straighforward to implement. However, language models need to have a complete list of tokens that they might encounter, and that’s not feasible for whole words — not only because there are so many words in the dictionary, but also because it would be difficult to keep up with domain-specific terminology and any new words that are invented.
So it’s not surprising that OpenAI settled for a solution somewhere in between those two extremes. Other companies have released tokenizers that follow a similar approach, for example Sentence Piece by Google.
Now that we have a better understanding of tokens, let’s go back to our original diagram and see if we can understand it a bit better. Generative models take
That makes a bit more sense now.
But if you’ve played with OpenAI’s ChatGPT, you know that it produces many tokens out, not a single token. That’s because this basic idea is applied in an expanding-window pattern. You give it
For example, if I type “We need to” as input to my model, the algorithm may produce the results shown below:

While playing with ChatGPT, you may also have noticed that the model is not deterministic: if you ask it the exact same question twice, you’ll likely get two different answers. That’s because the model doesn’t actually produce a single predicted token; instead it returns a probability distribution over all the possible tokens. In other words, it returns a vector in which each entry expresses the probability of a particular token being chosen. The model then samples from that distribution to generate the output token.
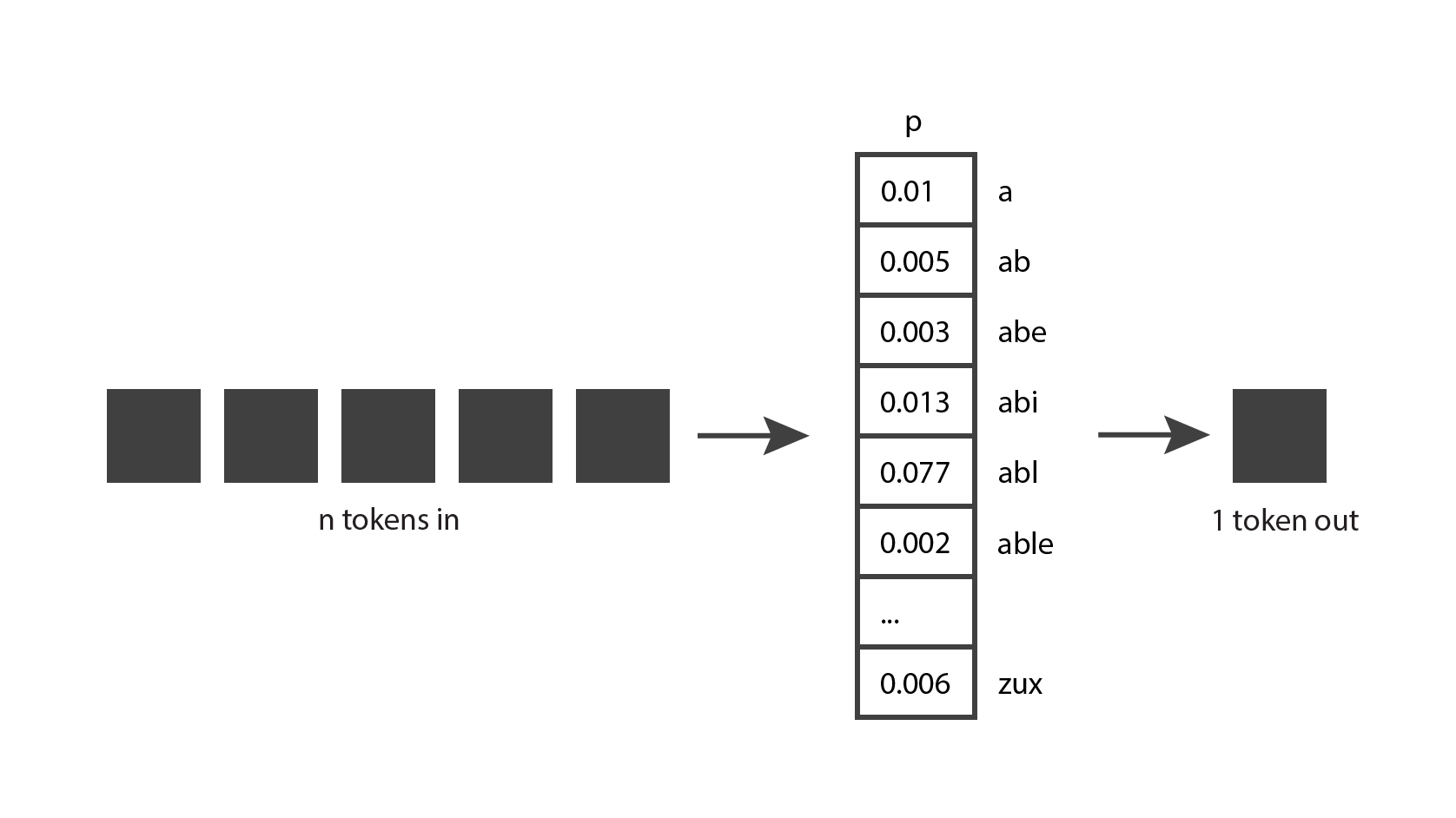
How does the model come up with that probability distribution? That’s what the training phase is for. During training, the model is exposed to a lot of text, and acquires the ability to predict good probability distributions, given a sequence of input tokens. GPT models are trained with a large portion of the internet, so their predictions reflect a mix of the information they’ve seen.
You now have a very good understanding of the idea behind generative models. Notice that I’ve only explained the idea though, I haven’t yet given you an algorithm. It turns out that this idea has been around for many decades, and it has been implemented using several different algorithms over the years. Next we’ll look at some of those algorithms.
A brief history of generative language models
Hidden Markov Models (HMMs) became popular in the 1970s. Their internal representation encodes the grammatical structure of sentences (nouns, verbs, and so on), and they use that knowledge when predicting new words. However, because they are Markov processes, they only take into consideration the most recent token when generating a new token. So, they implement a very simple version of the ”
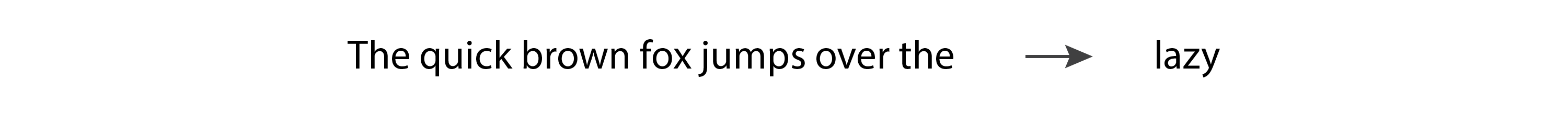
If we input “The quick brown fox jumps over the” to a language model, we would expect it to return “lazy.” However, an HMM will only see the last token, “the,” and with such little information it’s unlikely that it will give us the prediction we expect.
N-grams became popular in the 1990s, and unlike HMMs, they’re capable of taking a few tokens as input. An N-gram model would probably do pretty well at predicting the word “lazy” for the previous example. However, N-grams don’t scale well to a larger number of input tokens.
Then in the 2000s, Recurrent Neural Networks (RNNs) became quite popular because they’re able to accept a much larger number of input tokens. In particular, LSTMs and GRUs, which are types of RNNs, became widely used and could generate fairly good results. However, RNNs have instability issues with very long sequences of text. The gradients in the model tend to grow exponentially (called “exploding gradients”) or decrease to zero (called “vanishing gradients”), preventing the model from continuing to learn from training data.
In 2017, the paper that introduced Transformers was released by Google, and we entered a new era in text generation. The architecture used in Transformers allowed a huge increase in the number of input tokens, eliminated the gradient instability issues seen in RNNs, and was highly parallelizable, which meant that it was able to take advantage of the power of GPUs. Transformers are based on the “attention mechanism,” where the model is able to pay more attention to some inputs than others, regardless of where they show up in the input sequence. For example, let’s consider the following sentence:
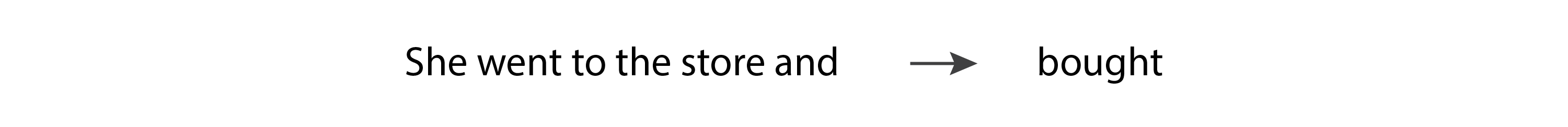
In this scenario, when the model is predicting the verb “bought,” it needs to match the past tense of the verb “went.” In order to do that, it has to pay a lot of attention to the token “went.” In fact, it may pay more attention to the token “went” than to the token “and,” despite the fact that “went” appears further back in the input sequence.
Transformers are still widely used today, and they’re the technology chosen by OpenAI for their latest text generation models. Let’s take a closer look at those language models.
How different GPT models are implemented
At the time of writing, the three latest text generation models released by OpenAI are GPT-3.5, ChatGPT, and GPT-4, and they are all based on the Transformer architecture. In fact, “GPT” stands for “Generative Pre-trained Transformer.”
GPT-3.5 is a completion-style model, which means that if we give it a few words as input, it’s capable of generating a few more words that are likely to follow them in the training data.
ChatGPT, on the other hand, is a conversation-style model, which means that it performs best when we communicate with it as if we’re having a conversation. It’s based on the same transformer base model as GPT-3.5, but it’s fine-tuned with conversation data. Then it’s further fine-tuned using Reinforcement Learning with Human Feedback (RLHF), which is a technique that OpenAI introduced in their 2022 InstructGPT paper. In this technique, we give the model the same input twice, get back two different outputs, and ask a human ranker which output it prefers. That choice is then fed back into the model through fine-tuning. This technique brings alignment between the outputs of the model and human expectations, and it’s critical to the success of OpenAI’s latest models.
GPT-4 on the other hand, can be used both for completion and conversation, and has its own entirely new base model. This base model is also fine-tuned with RLHF for better alignment with human expectations.
Conclusion
Hopefully you learned something new in this article. I plan to write more of these explainers about language models, and would love to hear what topics you would like to see covered. Thank you for reading!
Note
All images are by the author unless otherwise noted. You can use any of the original images in this blog post for any purpose, with attribution (a link to this article).